Thesis Question
In digital systems, we access information through databases and software. Graphical interfaces make this process easy and almost invisible. But also might lead to false assumptions and misconceptions derived from the lack of knowledge of the systems we engage with.
This project is concerned with the relation between users and information mediated by software. It will explore how the process of gathering information from databases is shaped by the algorithm that drives it. How much do we know about systems we use daily? How aware are we about possible biases in data retrieval?
Research
Data, Database, and Information
This project aims to provoke reflection on our relationship with online sources of information. Though it might make use of online databases, and retrieve data from them, its main concern is information. Therefore, a distinction between the 3 terms is necessary.
In this project, the term database defines any system of information, not restricted to a digital format. As researcher Christiane Paul points out, “it is essentially a structured collection of data that stands in the tradition of ‘data containers’ such as a book, a library, an archive, or Wunderkammer.” [@paul_database_2007]
Data, as a consequence, is the content of the database, no matter its nature — image, text, or number. At last, information, often referred to as “processed data,” is understood in this project as a piece of content (data) that has been through a process of analysis or interpretation. New media artist and academic Mitchell Whitelaw defines data as “the raw material of information, its substrate”, whereas information “is the meaning derived from data in a particular context.” [@whitelaw_fcj-067_]
Information Arts
Given that the production and circulation of information is the main concern of this project, it is inserted in the field of information arts. This practice is defined by Christiane Paul and Jack Toolin as works that “explore or critically address the issues surrounding the processing and distribution of information by making information itself the medium and carrier of this exploration.” [@paul_encyclopedia_]
Considering that this work utilizes algorithms to process digital information, there is an overlap between information arts and digital, or new media, art. However, both the subject and medium of this project refer to information. Digital media, on the other hand, is only a part of the techniques here employed. Therefore, the category information art will be adopted instead of digital or new media art.
Methodology and Series Concept
This project is the first one of a series intended to provoke discussion on our use of online sources of information. The series is defined by a set of rules:
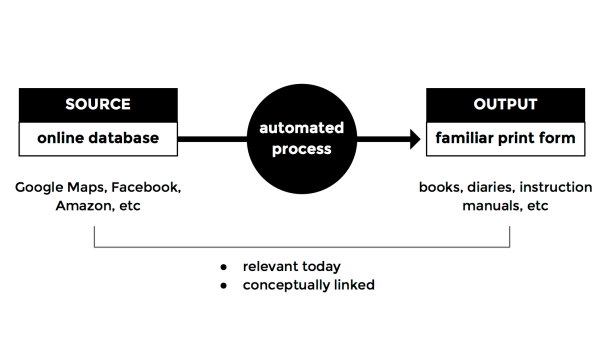
- Each work will utilise an online database as a source for a print output. Database here is used in the broad sense of a set of data — from a simple html page to a social network stream, for example.
- The print output must relate to the source conceptually, making a clear link between the two. It should also evoke familiar print forms — books, diaries, posters, guides, instruction manuals, etc.
- The prints will be generated through an automated process.
- Both online sources and print forms should not only have a clear link, but also be relevant today.
Paul and Toolin present a diagram that outlines the general practice of information arts. In this model, the work can either be finished in the stage of information, serving as a new data source, or generate a database or visualization that will then be redistributed. The latter is the case of this project, which will reorganize the data source constructing a new database and then translate it into new forms of communication.

The printed media is utilised in this project as a communication device, for its capacity to evoke cultural meaning embedded into its familiar forms. ABC books, for instance, are directly associated with education, children, language, no matter how diverse their formats and content.
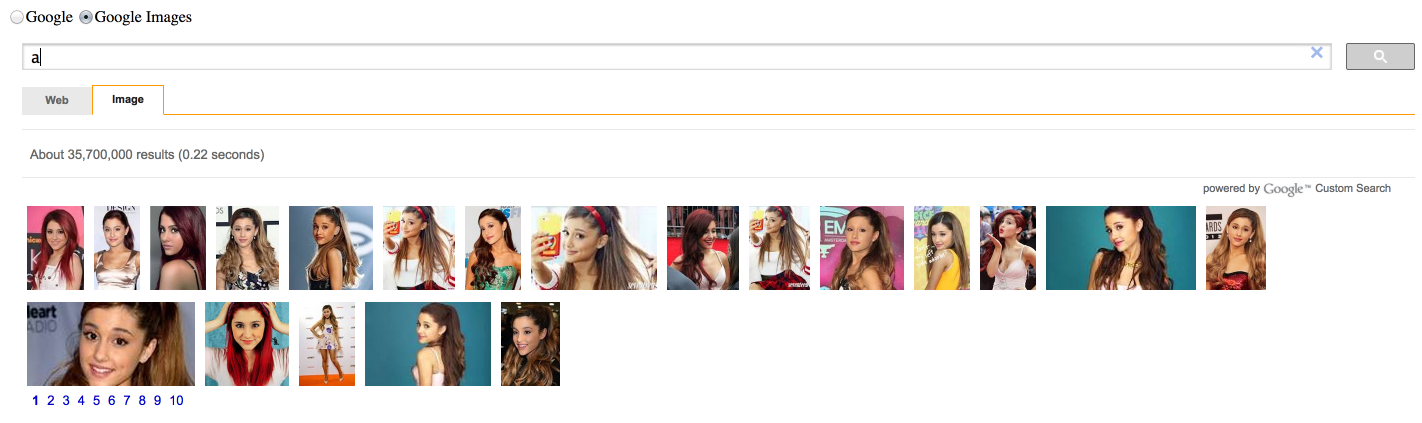
The translation from digital to print also serves the purpose of creating an uncanny effect. Though both online content and printed media must be familiar, their displacement should generate an odd hybrid form. In addition, this process helps bring focus to the dataset, by removing it from its original UI. For example, a comparison of all Google’s autocomplete suggestions from A to Z would not be possible through the search box, because it retrieves results one at a time.
Implementation Prototype: Google’s Supersearch
“Google’s ABC,” the prototype described in the previous paper, did not allow users to easily compare the autocomplete suggestions accross different services — Google Web and Google Images, in that case. This new prototype, “Google’s Supersearch,” was developed in response to that, and allows users to compare autocomplete suggestions from 7 different Google services: Web, Youtube, Recipes, Products, News, Images, and Books.
However, this prototype is not conceptually linked to the series outlined in the methodology section. Most of the questions it tries to answer are technical: what Google services offer access to their autocomplete suggestions? Is it possible to retrieve their results without using any API?
In their paper “What do Prototypes Prototype?,“ Stephanie Houde and Charles Hill proposed a model for categorizing prototypes according to their functions. [@houdc_what_1997] Based on that, “Google’s Supersearch” is considered here an implementation prototype, since most of its questions are related to technical aspects of a larger project.

“Google’s Supersearch” has a simple functionality. As users type in the search box, the page displays autocomplete suggestions — from each of the 7 different Google services — as lists into separate boxes. The options are clickable and redirect to a Google search page with the results for the selected term. For example, clicking on “chicken dance” under the Youtube list redirects to an youtube search page with all the results for “chicken dance.” This is achieved using the same Google Autocomplete undocumented “API” [@google] employed in “Google ABC.”
The interface is minimal and has no symbolic associations — the ABC metaphor was removed from it. The only text displayed besides the title and the results is “What does each Google service suggest you?”
The prototype was received by users as a rather practical and useful application, capable of aggregating different functions from Google in a single place.

Role Prototype: Google ABC Book (Printed)
The design questions addressed by this prototype were related to the communicative aspects of the project. First, do people recognise it as an ABC book? Do they understand it is intended for children? Second, what do they think about the use of autocomplete suggestions an educational material? Do they perceive any critical message?
The prototype was made by storing the top autocomplete suggestions for each letter, using Google Images. After that, images for each term were searched and downloaded. Then the book was designed in Adobe Illustrator, using one of the many layouts for instant books described by Esther K. Smith in “How to Make Books.“ [@smith_how_2007] It was printed in a single sheet of paper in letter format. This layout does not require any binding or advanced tools besides scissors and glue.


The back of the book displays the time and date of that edition, along with the following lines: “Earlier and earlier kids are learning things online. So why not start as soon as possible? This ABC book curated by Google Images brings to your children the top searches for each letter! Kids will love it!”
The response to this prototype was positive, in general. Though some people did not understand exactly how the content was being generated, the critical association between the online source and the print form was clear for most users. Some even stated that giving kids those books could be an interesting experiment, since the celebrities present on it were well-know even for children in an early age. This was a positive outcome of the user test, since the intention of this project is not to point out negative aspects of technology, but instead provoke discussion and reflection.

Integration Prototype: Google ABC Book (Online)
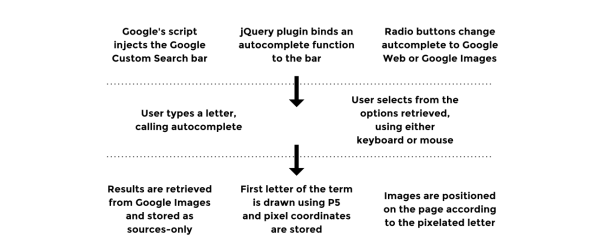
This prototype combines technical aspects from both previous ones. Its online presence utilizes the same undocumented API [@google] used to retrieve autocomplete suggestions from various Google services. The layout is set so that users can print the page, cut, fold, and make an instant book exactly like the one described in the previous section.
Accessing and manipulating the images was the most challenging part of the development of this prototype. As described in the previous paper, the new Google Custom Search [@custom] does not allow for customization of the results layout. Also, the Google script that receives and displays the images on the page runs on the server side. Therefore, it is not possible to manipulate the images with a script on the client side directly.
On previous prototypes, a quick fix was to use the official custom search and then scrape the results from the page to manipulate them. That would be laborious and not effective for the current prototype, in which 26 searches need to be performed in sequence.
The solution was to use a web scraper running on the server side. The way it works is by emulating a client visiting an url, in this case 26 Google Images pages, one for each term. Then a script grabs the first image from the results and send it back to the client. This was achieved using node.js, a server language based on javaScript syntax, with a combination of modules for web scraping and connecting client and server.
Once that problem was solved, the basic layout was designed, aimed to make the page ready for print. It was achieved through a combination of CSS rules and javaScript.
Some iterations at this point included sliders to change the colors of pictures and letters. This was an attempt to solve the contrast problems, but was discarded to avoid adding extra steps to the generative design process. Instead, the version sent to users displayed the letters in black, with a white outline.



Technically, the prototype works as follows:
- User selects service. A script runs through the 26 letters of the alphabet and retrieves autocomplete suggestions for each letter using a Google non-documented API. (See design brief #3 for details).
- By hitting ok to confirm, the user triggers the instant book layout.
- After the layout is complete, the page calls a web scraper, sending the suggestions stored in the first step — ‘Ariana Grande’ for A, ‘Beyonce’ for B, etc.
- The scraper runs on node.js, some node modules, and phantomJS. It loads one Google Images page for each term sent by the client — ‘Ariana Grande,’ ‘Beyoncé,’ ‘cat,’ etc.
- The scraper stores the address of the first image result and send it back to the client.
- The image is appended to its position, below the initials.
- If ‘print’ is hit, a new html page is created and the html from the book is sent to it.

User Tests
The prototype was sent as a web link (http://54.204.173.108:3011) to 22 people, from which 10 sent a response. Only a few had a general idea of the concept, and most of them have not seem the printed prototype first. People were invited to participate through email or in person. Because different aspects of the project were being tested at once, no guidelines were given on what to comment.
The main areas on which this prototype focused were:
- Implementation: check technical aspects, especially related to the web scraper, concerning speed and stability.
- Role: questions related to the communicative aspects: is the “ABC Book” metaphor clear? Do people sense a critical tone on the message or not? Does it provoke discussion?
As for the look and feel, it was only partially addressed. The default html styling adopted is far from representing a definitive visual design for the project. Although, the basic wireframe, with the process split into 3 steps — source selection, printed form, and tutorial — was meant to be final.
Up until it was sent to the users, this prototype has been running on a local server, with no major technical problems. That was not the case when it was published on a remote server, though.The time for scraping and loading the images went from less than a minute to about 5 minutes. This had a drastic effect on the user experience. Some participants responded immediately expressing their concern and some ended up not taking part in the test at all.
Technical adjustments were made and the prototype was updated in less than 12 hours after the invitation. In the new version, it takes about 2 seconds to load the first image and 15 to 20 seconds to load all 26.
Once this problem was solved, the responses from the participants did not point out other technical problems. The information gathered after that can be grouped into 4 areas: communication, experience, layout, and instructions. Each one was also split here into feedback and suggestions — except for the first, for which users did not suggest any direct change.
- Communication
- Feedback
- It is clearly a critical project, not a commercial one.
- The print aspect works well to capture a moment of something that is constantly changing.
- It is not clear if the message is genie or ironic.
- It could be utilized as something practical, to teach computer literacy.
- Feedback
- Experience
- Feedback
- The questionnaire format is confusing, because there is no interaction after the first step.
- Instructions and options don’t leave much breathing room.
- There is no option to personalize the results.
- Some images are not recognizable, and there is no way to see what they refer to.
- Suggestions
- Expand the questionnaire/interaction to the net steps.
- Allow for theme-based custom results — pop-singers, for instance.
- Add option to change location, allowing for comparison between countries.
- Add interaction to images, to display their description/
- Include option to change each of the results.
- Feedback
- Layout
- Feedback
- It is hard to see the images, they are too small and the letters cover a big part of them.
- The upside-down letters are not legible.
- The layout is not visually exciting.
- The layout only works for print.
- Suggestions
- Add option to control font size.
- Create two separate layouts: one for the screen and another for print.
- Show the final product somehow.
- Feedback
- Instructions
- Feedback
- It is hard to follow the instructions.
- Some sentences are confusing.
- Suggestions
- Moving images or videos would be more clear.
- Feedback
Findings and Next Steps
Some of the responses to the communicative aspect of the project were contradicting. Most people understood the project as somewhat critical, though not sure about its precise intention. That is not a major concern, because leaving room for interpretation and discussion is part of the goal of this project.
As for the problem with the instructions, it can be easily addressed through the use of video or moving images, as suggested in one of the responses.
After the test, some of the users were presented to the printed version of the prototype – none of them printed it from the page. The responses were all positive, as opposed to their opinions about the web page layout. This was an unexpected an yet reasonable problem: since the page was developed as a simple bridge through the source and the print output, not much thought was put into the online experience. As a consequence, if users do not print it, their experience is limited and frustrating. Therefore, experience and layout are the areas that demand deeper and most immediate changes for the next iterations.
The next steps of this project will conduct two simultaneous investigations:
- Online experience Define a better balance between the print and digital version. The latter should work independently from the former, besides being more interactive and having its own layout.
- Series Investigate other online sources and print forms that fulfill the rules and conceptual goals of this project. A methodology still in test is to list the most popular and relevant online sources in use today and find their corresponding print forms.
Bibliography
“Custom Search — Google Developers.” 2014. Accessed October 17. https://developers.google.com/ custom-search/.
“Google Autocomplete ‘API’ Shreyas Chand.” 2014. Accessed October 17. http://shreyaschand.com/blog/ 2013/01/03/google-autocomplete-api/.
Houdc, Stephanie, and Charles Hill. 1997. “What Do Prototypes Prototype?” http://www.itu.dk/~malmborg/ Interaktionsdesign/Kompendie/Houde-Hill-1997.pdf.
Paul, Christiane. 2007. The Database as System and Cultural Form: Anatomies of Cultural Narratives. na. http://visualizinginfo.pbworks.com/f/db-system-culturalform.pdf.
Paul, Christiane, and Jack Toolin. 2014. “Encyclopedia of Library and Information Sciences.” Accessed November 26. http://www.tandfonline.com/doi/abs/10.1081/E-ELIS3-120043697.
Smith, Esther K. 2007. How to Make Books: Fold, Cut & Stitch Your Way to a One-of-a-Kind Book. 1St Edition edition. New York: Potter Craft.
Whitelaw, Mitchell. 2014. “FCJ-067 Art Against Information: Case Studies in Data Practice.” Accessed September 22. http://eleven.fibreculturejournal.org/fcj-067-art-against-information-case-studies-in-data-practice/.